Redis Clone: Reducing Memory Pressure
After the taking a look at the original naive implementation, I wanted to try reducing the memory churn. By accident the IO optimizations already reduced the memory usage. Let’s go a bit further, trimming down some memory usage.
I often look out for two things: - Object allocations of objects which are immediately thrown away again. Yes, the JVM allocator and GC do an amazing job handling short-lived objects. However, it’s not magic and the memory bandwidth is limited. So, removing unnecessary short-lived objects is often easy and gives you more memory bandwidth headroom. - Ensuring long-lived objects are in a compact form and a useful format for the purpose.

Anyway, I’m trying to shave off some allocations in this blog post. Note, as I reduce allocations the code becomes less Java-y and I introduce C-like fragility, where life-time of memory matters. In a real-world app I would only use such optimizations only if you really need more performance.
Improving the Writes
If we take a look at the writes, we see this:
var reply = executeCommand(args);
if (reply == null) {
writer.write("$-1\r\n");
} else {
writer.write("$" + reply.length() + "\r\n" + reply + "\r\n");
}
// The write method
public void write(String toWrite) throws Exception {
var bytes = toWrite.getBytes(UTF_8);
ensureAvailableWriteSpace(writeBuffer);
writeBuffer.writeBytes(bytes);
...
}We first allocate a string, then allocate a byte array for the UTF-8 encoded form, and then copy these bytes into the writeBuffer. I avoided the intermediate by directly writing the elements into the buffer. For that I exposed lower-level operations and used those:
# In the Writer
public void ensureAvailableWriteSpace(){
ensureAvailableWriteSpace(writeBuffer);
}
public void writeBytes(byte[] toWrite) {
writeBuffer.writeBytes(toWrite);
}
final StringBuilder lengthAsAsciiBuffer = new StringBuilder(2);
// somewhat hacky way to turn a int to a string.
// I couldn't find a utility method in the JDK doing this without allocations
public void writeLengthAsAscii(int length) {
lengthAsAsciiBuffer.delete(0, lengthAsAsciiBuffer.length());
lengthAsAsciiBuffer.append(length);
writeBuffer.writeCharSequence(lengthAsAsciiBuffer, US_ASCII);
}
public void writeString(String reply) {
writeBuffer.writeCharSequence(reply, UTF_8);
}
public void flushIfBufferedEnough() throws IOException {
final var AUTO_FLUSH_LIMIT = 1024;
if (AUTO_FLUSH_LIMIT < writeBuffer.readableBytes()) {
// A bit confusing in this use case: We read the buffers content into the socket: aka write to the socket
var written = writeBuffer.readBytes(socket, writeBuffer.readableBytes());
// If we want proper handling of the back pressure by waiting for the channel to be writable.
// But for this example we ignore such concerns and just grow the writeBuffer defiantly
}
}
// In the RedisClone
private static final byte[] NOT_FOUND = "$-1\r\n".getBytes(UTF_8);
private static final byte[] DOLLAR = "$".getBytes(UTF_8);
private static final byte[] NEW_LINE = "\r\n".getBytes(UTF_8);
// And then when writing the answer.
var reply = executeCommand(args);
writer.ensureAvailableWriteSpace();
if (reply == null) {
writer.writeBytes(NOT_FOUND);
} else {
writer.writeBytes(DOLLAR);
writer.writeLengthAsAscii(reply.length());
writer.writeBytes(NEW_LINE);
writer.writeString(reply);
writer.writeBytes(NEW_LINE);
}
writer.flushIfBufferedEnough();Improving the Reader
The reading code path allocates a string for each line. On that String we search for specific ASCII characters and that’s about it:
String line = reader.readLine();
if (line == null)
break;
if (line.charAt(0) != '*')
throw new RuntimeException("Cannot understand arg batch: " + line);
var argsv = Integer.parseInt(line.substring(1));
for (int i = 0; i < argsv; i++) {
line = reader.readLine();
if (line == null || line.charAt(0) != '$')
throw new RuntimeException("Cannot understand arg length: " + line);
var argLen = Integer.parseInt(line.substring(1));
line = reader.readLine();
if (line == null || line.length() != argLen)
throw new RuntimeException("Wrong arg length expected " + argLen + " got: " + line);
args.add(line);
}What I did here is to return a 'sub' ByteBuf. That is still an allocation, but it avoids copying over the bytes.
public ByteBuf readLine() throws Exception {
var eof = false;
while (!eof) {
var readIndex = readBuffer.readerIndex();
var toIndex = readBuffer.readableBytes();
// Find the next line in the read content
var foundNewLine = readBuffer.indexOf(readIndex, readIndex + toIndex, (byte) '\n');
if (foundNewLine >= 0) {
var length = foundNewLine - readIndex;
var line = readBuffer.slice(readIndex, length - 1);
readBuffer.readerIndex(readIndex + length + 1);
return line;
} else {
...
}
}
}
// And in the Redis clone:
// Parse int, base 10, assuming ASCII, non-negative number
private int parseInt(ByteBuf toRead){
var num = 0;
while(toRead.readableBytes() > 0){
var b = toRead.readByte();
var n = b - 48;
num = num*10 + n;
}
return num;
}
// And then reading the lines
ByteBuf line = reader.readLine();
if (line == null)
break;
if (line.readByte() != '*')
throw new RuntimeException("Cannot understand arg batch: " + line);
var argsv = parseInt(line);
for (int i = 0; i < argsv; i++) {
line = reader.readLine();
if (line == null || line.readByte() != '$')
throw new RuntimeException("Cannot understand arg length: " + line);
var argLen = parseInt(line);
line = reader.readLine();
if (line == null || line.readableBytes() != argLen)
throw new RuntimeException("Wrong arg length expected " + argLen + " got: " + line);
args.add(line.toString(UTF_8));
}Did you notice that we introduced memory management complexities here: The sliced buffer returned by readLine() points into the memory of the original buffer. It is only valid until the next time readLine() is called. If the sliced buffer is handed off further, and the readLine() is called, it might point into different memory. In general, avoid creating APIs like this, unless you need the performance.
Avoiding creating the Sliced Buffer
While we removed the allocation and copying of the byte[] for a string, we still allocate a
sliced buffer. That sliced buffer is only in a valid state until the next call to readLine().
Because that is the case, we also can return the same buffer, reused across readLine() calls.
Then no sliced buffer needs to be allocated.
Of course, now we copy the bytes again. However, it is typically not that many bytes.
Hopefully, both buffers are hot in some CPU cache,
making the copying outperform the allocation.
I am not going to microbenchmark this though to ensure that this is the case.
private final ByteBuf line = Unpooled.buffer(512);
public ByteBuf readLine() throws Exception {
// ... existing code
if (foundNewLine >= 0) {
var LINE_FEED_SIZE = 1;
var length = foundNewLine - readIndex;
// Reset line buffer, then 'copy' the bytes over.
// We trade avoiding allocating with copying (not that many) bytes
line.clear();
line.ensureWritable(length-LINE_FEED_SIZE);
readBuffer.readBytes(line,length-LINE_FEED_SIZE);
readBuffer.readerIndex(readIndex + length + LINE_FEED_SIZE);
return line;
} else {
// ... existing codeReduce the String Allocations
Now, lets take a look at our actual 'business' logic, the in memory map:
private final ConcurrentHashMap<String, String> state = new ConcurrentHashMap<>();Do we care that it is a String for the task we do? Nope!
We receive a bunch of bytes from the network and store them.
When the client asks for a key, we get again a bunch of bytes and send an answer a bytes[].
We never care about the content or that it is an actual String.
So, let’s change it to bytes:
private final ConcurrentHashMap<Key, byte[]> state = new ConcurrentHashMap<>();
// Required because a hash map we need meaningful .hashCode() and .equals(), unfortunately a
// raw byte[]'s .hashCode() and .equals() are the default Object.hashCode() and .equals().
class Key{
private final byte[] key;
public Key(byte[] key) {
this.key = key;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Key key1 = (Key) o;
return Arrays.equals(key, key1.key);
}
@Override
public int hashCode() {
return Arrays.hashCode(key);
}
}And with that, the argument list also can be made of bytes. Plus we can write the bytes directly, without any encoding required. Awesome!
private static final byte[] GET = "GET".getBytes(US_ASCII);
private static final byte[] SET = "SET".getBytes(US_ASCII);
byte[] executeCommand(List<byte[]> args) {
if(Arrays.equals(GET, args.get(0))){
return state.get(new Key(args.get(1)));
} else if(Arrays.equals(SET, args.get(0))){
return state.put(new Key(args.get(1)), args.get(2));
} else{
throw new IllegalArgumentException("Unknown command: " + new String(args.get(1), US_ASCII));
}
}
public void handleConnection(SocketChannel socket) throws Exception {
var args = new ArrayList<byte[]>();
// ... existing code
byte[] arg = new byte[line.readableBytes()];
line.readBytes(arg);
args.add(arg);
// ... existing code
var reply = executeCommand(args);
writer.ensureAvailableWriteSpace();
if (reply == null) {
writer.writeBytes(NOT_FOUND);
} else {
writer.writeBytes(DOLLAR);
writer.writeLengthAsAscii(reply.length);
writer.writeBytes(NEW_LINE);
writer.writeBytes(reply);
writer.writeBytes(NEW_LINE);
}
writer.flushIfBufferedEnough();
// ... existing code
}Going Further: Avoid Argument List and Keys
There are still quite some allocations: We create a copy of the arguments
and then also create Key objects to find the items in the map:
var args = new ArrayList<byte[]>();
//...
byte[] arg = new byte[line.readableBytes()];
line.readBytes(arg);
args.add(arg);
//...
var reply = executeCommand(args);
byte[] executeCommand(List<byte[]> args) {
if(Arrays.equals(GET, args.get(0))){
return state.get(new Key(args.get(1)));
} else if(Arrays.equals(SET, args.get(0))){
return state.put(new Key(args.get(1)), args.get(2));
} else{
throw new IllegalArgumentException("Unknown command: " + new String(args.get(1), US_ASCII));
}
}However, instead of copying the arguments and interpreting them later, we can parse the arguments as they come in.
As we have now raw ByteBuf`s we can do one more trick:
The ByteBufs `.hashCode() and .equals() used by hash maps is based on the readable bytes.
So, instead of allocating a Key, we can use the incoming ByteBuf directly as a key.
Note: This is very fragile: Now the hash maps keys are mutable objects with changing hash code.
If something mutates a key or gives the key in slightly the wrong state,
you will key misses, and potentially hard to debug heisenbugs.
private final ConcurrentHashMap<ByteBuf, byte[]> state = new ConcurrentHashMap<>();
// In handleConnection
if (line.readByte() != '*')
throw new RuntimeException("Cannot understand arg batch: " + line);
byte[] reply = parseAndHandleCommand(reader, line);
writer.ensureAvailableWriteSpace();
private static final ByteBuf GET = Unpooled.wrappedBuffer("GET".getBytes(US_ASCII));
private static final ByteBuf SET = Unpooled.wrappedBuffer("SET".getBytes(US_ASCII));
private byte[] parseAndHandleCommand(Reader reader, ByteBuf line) throws Exception {
// Instead of copying the arguments, parse and interpret the arguments as they are read in.
// Imagine here a decent 'parser' of the Redis wire protocol grammar
var argsv = parseInt(line);
assert (argsv == 2 || argsv == 3);
var command = readArgument(reader);
byte[] reply;
if (command.equals(GET)) {
assert (argsv == 2);
var key = readArgument(reader);
// DANGER-ZONE: We compare mutable objects in a hash map! It violates any recommendation and is super bug prone.
// However, it does work as the ByteBuf's .hashCode() and .equals() compare the readable bytes,
// which is the key of the line.
reply = state.get(key);
} else if (command.equals(SET)) {
assert (argsv == 3);
// DANGER-ZONE: See above. We need a copy this time of the ByteBuf, because it will survive the scope of the parsed line,
// so it can't be a pointer into the current line.
var key = readArgument(reader).copy();
// Content needs to be copied as well, same as above
var contentLine = readArgument(reader);
byte[] content = new byte[contentLine.readableBytes()];
contentLine.readBytes(content);
reply = state.put(key, content);
} else {
throw new IllegalArgumentException("Unknown command: " + command.toString(US_ASCII));
}
return reply;
}
private ByteBuf readArgument(Reader reader) throws Exception {
var line = reader.readLine();
if (line == null || line.readByte() != '$')
throw new RuntimeException("Cannot understand arg length: " + line);
var argLen = parseInt(line);
line = reader.readLine();
if (line == null || line.readableBytes() != argLen)
throw new RuntimeException("Wrong arg length expected " + argLen + " got: " + line);
return line;
}Benchmark
After all this hard work, making our code reducing a lot of allocations, how did we do? Well, the amount of operations is about the same, still in the 4.2 million operations per second range. However, what did improve it the long tail: We nearly halved the latency in the P99.9%.
ALL STATS ============================================================================================================================ Type Ops/sec Hits/sec Misses/sec Avg. Latency p50 Latency p99 Latency p99.9 Latency KB/sec ---------------------------------------------------------------------------------------------------------------------------- Sets 384246.41 --- --- 1.81378 1.59100 4.44700 47.87100 114031.41 Gets 3842421.22 1561987.43 2280433.80 1.81145 1.59100 4.41500 47.87100 544750.73 Waits 0.00 --- --- --- --- --- --- --- Totals 4226667.64 1561987.43 2280433.80 1.81166 1.59100 4.44700 47.87100 658782.14
ALL STATS ============================================================================================================================ Type Ops/sec Hits/sec Misses/sec Avg. Latency p50 Latency p99 Latency p99.9 Latency KB/sec ---------------------------------------------------------------------------------------------------------------------------- Sets 390048.09 --- --- 1.78628 1.63100 4.07900 27.00700 156260.99 Gets 3900437.78 1601633.30 2298804.48 1.78452 1.63100 4.07900 26.75100 557038.34 Waits 0.00 --- --- --- --- --- --- --- Totals 4290485.87 1601633.30 2298804.48 1.78468 1.63100 4.07900 26.75100 713299.33
And here are the flight recordings. We went from 40+ GBytes allocated in the 30 second run down to about 4GByte.
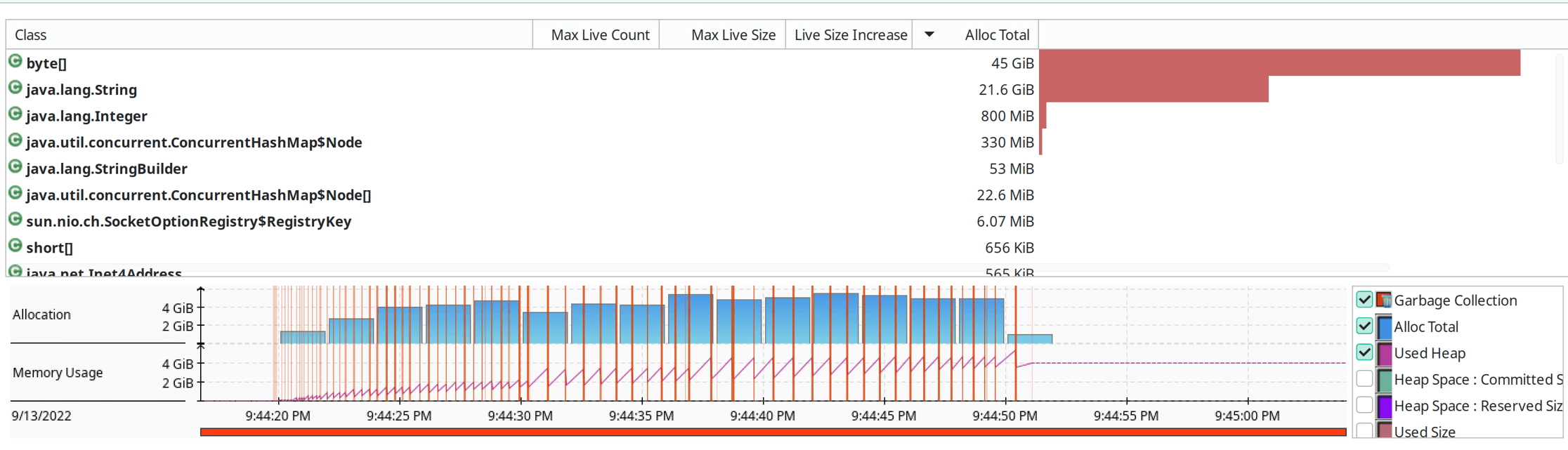
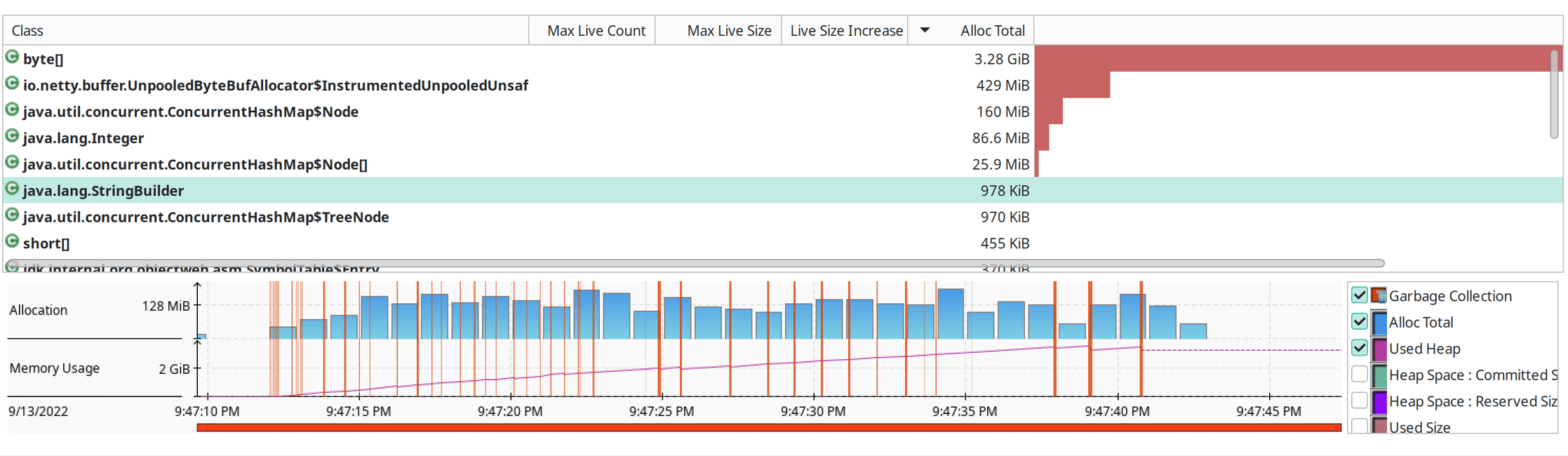
Full Code
▼Click for full source code:
package info.gamlor.redis;
import io.netty.buffer.ByteBuf;
import io.netty.buffer.Unpooled;
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.channels.SelectionKey;
import java.nio.channels.Selector;
import java.nio.channels.ServerSocketChannel;
import java.nio.channels.SocketChannel;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.Executors;
import static info.gamlor.redis.Writer.ensureAvailableWriteSpace;
import static java.nio.charset.StandardCharsets.US_ASCII;
import static java.nio.charset.StandardCharsets.UTF_8;
public class RedisMain {
public static void main(String[] args) throws Exception {
var scheduler = Executors.newVirtualThreadPerTaskExecutor();
var socket = ServerSocketChannel.open();
socket.bind(new InetSocketAddress("0.0.0.0", 16379));
System.out.println("App is listening on 0.0.0.0:16379");
var clone = new RedisClone();
while (true) {
var client = socket.accept();
scheduler.execute(() -> {
try (client) {
clone.handleConnection(client);
} catch (Exception e) {
e.printStackTrace();
}
});
}
}
}
class RedisClone {
private final ConcurrentHashMap<ByteBuf, byte[]> state = new ConcurrentHashMap<>();
private static final byte[] NOT_FOUND = "$-1\r\n".getBytes(UTF_8);
private static final byte[] DOLLAR = "$".getBytes(UTF_8);
private static final byte[] NEW_LINE = "\r\n".getBytes(UTF_8);
// Parse int, base 10, assuming ASCII, non-negative number
private int parseInt(ByteBuf toRead){
var num = 0;
while(toRead.readableBytes() > 0){
var b = toRead.readByte();
var n = b - 48;
num = num*10 + n;
}
return num;
}
public void handleConnection(SocketChannel socket) throws Exception {
// Configure the channel to be non-blocking: Our Writer and Reader class will control the blocking
socket.configureBlocking(false);
// Replace the JDK IO streams with our Reader and Writer
var writer = new Writer(socket);
var reader = new Reader(socket, writer);
while (true) {
var line = reader.readLine();
if (line == null)
break;
if (line.readByte() != '*')
throw new RuntimeException("Cannot understand arg batch: " + line);
byte[] reply = parseAndHandleCommand(reader, line);
writer.ensureAvailableWriteSpace();
if (reply == null) {
writer.writeBytes(NOT_FOUND);
} else {
writer.writeBytes(DOLLAR);
writer.writeLengthAsAscii(reply.length);
writer.writeBytes(NEW_LINE);
writer.writeBytes(reply);
writer.writeBytes(NEW_LINE);
}
writer.flushIfBufferedEnough();
}
}
private byte[] parseAndHandleCommand(Reader reader, ByteBuf line) throws Exception {
// Instead of copying the arguments, parse and interpret the arguments as they are read in.
// Imagine here a decent 'parser' of the Redis wire protocol grammar
var argsv = parseInt(line);
assert (argsv == 2 || argsv == 3);
var command = readArgument(reader);
byte[] reply;
if (command.equals(GET)) {
assert (argsv == 2);
var key = readArgument(reader);
// DANGER-ZONE: We compare mutable objects in a hash map! It violates any recommendation and is super bug prone.
// However, it does work as the ByteBuf's .hashCode() and .equals() compare the readable bytes,
// which is the key of the line.
reply = state.get(key);
} else if (command.equals(SET)) {
assert (argsv == 3);
// DANGER-ZONE: See above. We need a copy this time of the ByteBuf, because it will survive the scope of the parsed line,
// so it can't be a pointer into the current line.
var key = readArgument(reader).copy();
// Content needs to be copied as well, same as above
var contentLine = readArgument(reader);
byte[] content = new byte[contentLine.readableBytes()];
contentLine.readBytes(content);
reply = state.put(key, content);
} else {
throw new IllegalArgumentException("Unknown command: " + command.toString(US_ASCII));
}
return reply;
}
private static final ByteBuf GET = Unpooled.wrappedBuffer("GET".getBytes(US_ASCII));
private static final ByteBuf SET = Unpooled.wrappedBuffer("SET".getBytes(US_ASCII));
private ByteBuf readArgument(Reader reader) throws Exception {
var line = reader.readLine();
if (line == null || line.readByte() != '$')
throw new RuntimeException("Cannot understand arg length: " + line);
var argLen = parseInt(line);
line = reader.readLine();
if (line == null || line.readableBytes() != argLen)
throw new RuntimeException("Wrong arg length expected " + argLen + " got: " + line);
return line;
}
}
class Writer {
final SocketChannel socket;
final ByteBuf writeBuffer = Unpooled.buffer(4 * 1024);
final StringBuilder lengthAsAsciiBuffer = new StringBuilder(2);
public Writer(SocketChannel socket) throws IOException {
this.socket = socket;
assert !socket.isBlocking();
}
public void ensureAvailableWriteSpace(){
ensureAvailableWriteSpace(writeBuffer);
}
public void writeBytes(byte[] toWrite) {
writeBuffer.writeBytes(toWrite);
}
public void flushIfBufferedEnough() throws IOException {
final var AUTO_FLUSH_LIMIT = 1024;
if (AUTO_FLUSH_LIMIT < writeBuffer.readableBytes()) {
// A bit confusing in this use case: We read the buffers content into the socket: aka write to the socket
var written = writeBuffer.readBytes(socket, writeBuffer.readableBytes());
// If we want proper handling of the back pressure by waiting for the channel to be writable.
// But for this example we ignore such concerns and just grow the writeBuffer defiantly
}
}
public void writeLengthAsAscii(int length) {
lengthAsAsciiBuffer.delete(0, lengthAsAsciiBuffer.length());
lengthAsAsciiBuffer.append(length);
writeBuffer.writeCharSequence(lengthAsAsciiBuffer, US_ASCII);
}
public void flush() throws IOException {
if (writeBuffer.readableBytes() > 0) {
writeBuffer.readBytes(socket, writeBuffer.readableBytes());
}
}
// The Netty ByteBufs are not circular buffer: Writes always go to the end and may grow the buffer
// I assume the underlying reason is to make it more efficient to interact with Java NIO.
// So, if we're running out of writeable space, discard the bytes already written and
// copy the not yet read bytes to the start of the buffer, giving it enough space to write more at the end.
static int ensureAvailableWriteSpace(ByteBuf buf) {
final var MIN_WRITE_SPACE = 1024;
if (buf.writableBytes() < MIN_WRITE_SPACE) {
buf.discardReadBytes();
}
return Math.max(MIN_WRITE_SPACE, buf.writableBytes());
}
}
class Reader {
final SocketChannel socket;
final Writer writer;
final ByteBuf readBuffer = Unpooled.buffer(8 * 1024);
private final Selector selector;
private final ByteBuf line = Unpooled.buffer(512);
public Reader(SocketChannel socket, Writer writer) throws IOException {
this.socket = socket;
this.writer = writer;
this.selector = Selector.open();
socket.register(selector, SelectionKey.OP_READ, this);
}
public ByteBuf readLine() throws Exception {
var eof = false;
while (!eof) {
var readIndex = readBuffer.readerIndex();
var toIndex = readBuffer.readableBytes();
// Find the next line in the read content
var foundNewLine = readBuffer.indexOf(readIndex, readIndex + toIndex, (byte) '\n');
if (foundNewLine >= 0) {
var LINE_FEED_SIZE = 1;
var length = foundNewLine - readIndex;
// Reset line buffer, then 'copy' the bytes over.
// We trade avoiding allocating with copying (not that many) bytes
line.clear();
line.ensureWritable(length-LINE_FEED_SIZE);
readBuffer.readBytes(line,length-LINE_FEED_SIZE);
readBuffer.readerIndex(readIndex + length + LINE_FEED_SIZE);
return line;
} else {
// Otherwise, read from the socket
int readSize = ensureAvailableWriteSpace(readBuffer);
// A bit confusing in this use case: We write the content of the socket into the buffer: aka read from the channel
var read = readBuffer.writeBytes(socket, readSize);
if (read < 0) {
eof = true;
} else if (read == 0) {
// If we read nothing, ensure we flushed our previous reponses
writer.flush();
// And then wait until the socket becomes readable again
selector.select(key -> {
if (!key.isReadable()) {
throw new AssertionError("Expect to be readable again");
}
});
}
}
}
return null;
}
}