Until now we only used Joyent’s Triton. We deployed Docker container with Triton. Probably we want to store date somewhere. Manta is a Amazon S3 like storage service. However, Manta also can compute on your data. Let’s start!
When you only can store, you have to transfer it every time.
Manta can compute, so no need to transfer data around.
Preparation
Manta does have a REST API. However, in this blog post we’ll just use the Manta command line utilities.
Then we setup the Manta environment, so we copy from the Manta manual.
That’s all. We’re set up.
Let’s Store Some Files
First, let’s upload a few files.
To upload we use `mput`. The `-f` option will upload the specified file. The `~~/stor/hello-manta.txt` specifies where to upload the file in Manta. The `~~` is like the Unix home directory, just on Manta. `mput` also can upload from a pipe. Here we upload a RFC, right from the `curl` output. The `-p` option creates the parent directories if missing. `mls` lists a Manta directory content and `mfind` finds files based on name. Finally, `mrm` deletes files and directories.
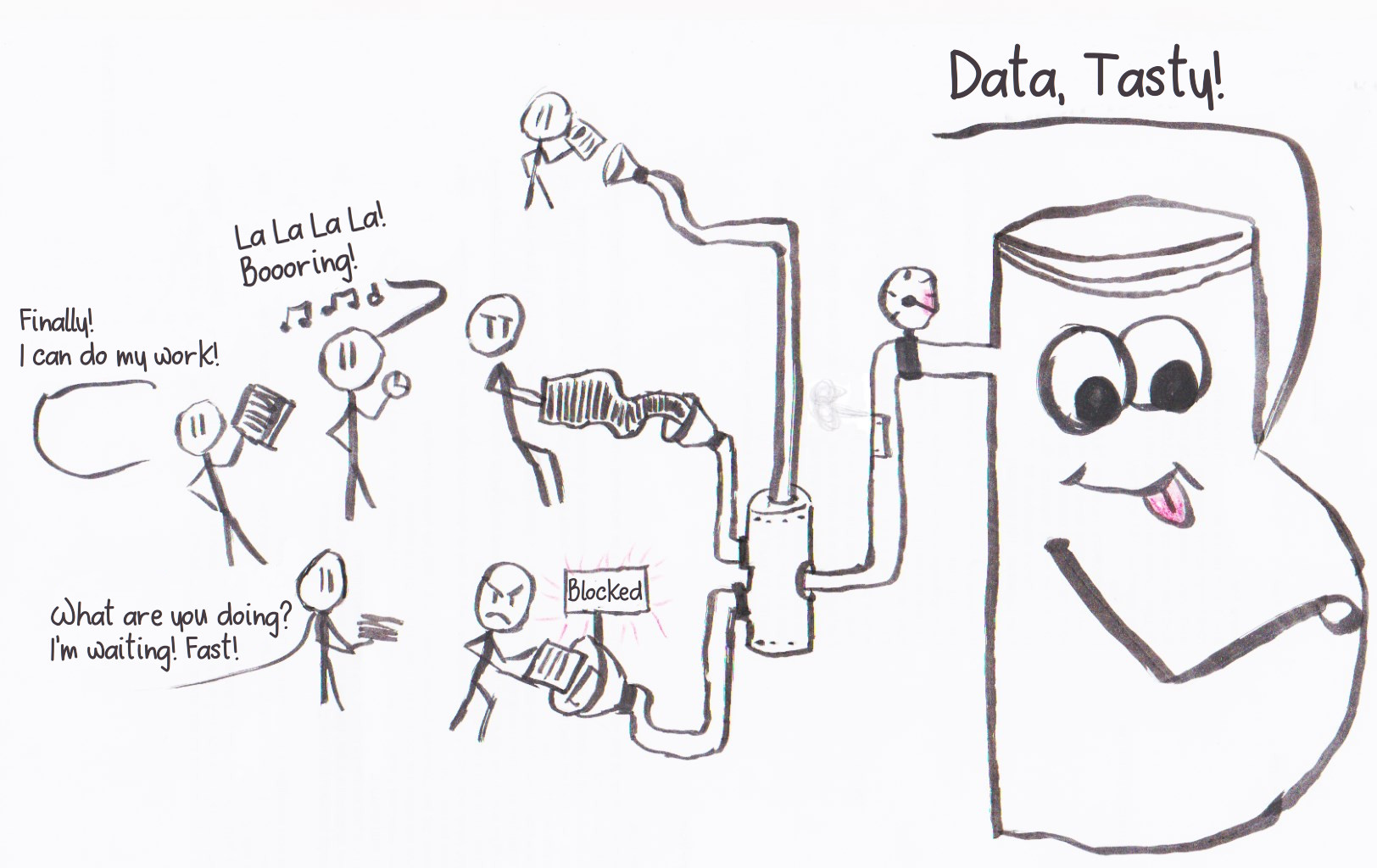
Manta’s Secret: Compute
First, let’s upload some videos.
So, we stored the videos on Manta. Maybe we want to create mobile friendly versions of these videos. So we download the video, transcode the video and upload it again? If video is a few GBytes, we down and upload it again? No! Manta can compute, so we can convert the video right there, on Manta. Aha, so we have to learn a new framework? No! Manta just uses regular Unix programs. Let’s start!.
We can login to the Manta file with `mlogin`. Really! This way we can run all Unix programs right next to the file and can compute anything right there. We want to create a smaller video, so we use `ffmpeg`. However, we want to transcode all videos. Yes, so let’s use `mjob` for that.
`mjob’ takes a Manta file path on stdin. `mjob create` starts a new computation. `-o` will wait to completion and show the results. After the `-m` option we specify the computation
1st example: Compute `~~/stor/blog/caminandes_03.mp4`’s sha1
2nd example: Find all files with `mfind` and compute the sha1s.
3nd example: We can use Unix pipes. So, let’s create a easy to read output.
Let’s try some useful computation. Let’s `unzip` caminandes_01.zip andcaminandes_02.zip, then store it as with `mpipe’ as another Manta file. `-w` waits until the computation completed. And now let’s create the small, mobile friendly videos. We transcode with `ffmpeg` and store the small file with `mpipe` to a new Manta file. TATAAAA! Here are our smaller videos. We can check out a small file with `mget’. We did all this directly on Manta. If these file were large we didn’t have to download, then upload again anything. We did everything in Manta.
Map Reduce
So far we only used `mjob create -m`. `mjob` can do map reduce. When we need some summary type of computation, we use the map reduce feature. Here a example, were we calculate a summary of the used video bit rates:
First, we extract the video’s info with `mbjob` and `ffprobe`. We look for the bitrat with `grep` and locate the right, 6th column with `awk`. Finally, we specify the reduct step after the `-r` parameter. Here we use `maggr` to do some statistics. (^_^)
Explore Manta
I skipped many features and topics. Take a look at the Manta documentation and try it out.