ADBCJ: Some Peformance Numbers
This time we look at some performance numbers, comparing JDBC with ADBCJ (github, blog-posts). Particular the performance of small web applications, once implemented with JDBC, once with ADBCJ. Each application is implemented with the Play Framework, which supports well asynchronous operations. I don’t want to go into all the gritty details. If you really want to read tons of details, go ahead.
The setup looked like this:
– Amazon EC2: Mysql Extra Large instance
– Two Amazon EC2: M1 Large instance as web tiers. Running the Play Application.
– Two Amazon EC2:M1 Medium instance as load tiers. Using Grinder to run scripts which use the web app.
We take a look at latency and throughput.
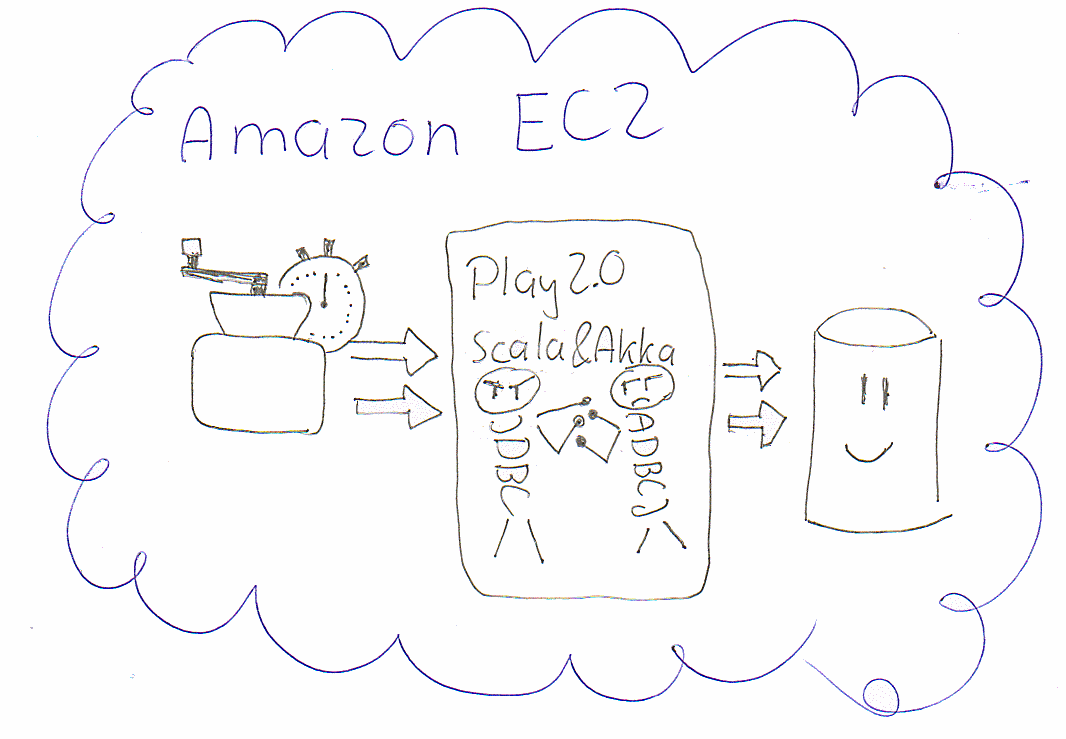
Test Setup
Blog-App
First let’s look a small blog app. The app serves posts, which have tags and authors. So the application gets the latest posts and fetches the tags for each post. Also it shows the most popular tags.

A blog
We take a look at the latency, with a web tier which is far away from its max capacity (around 50% CPU utilization):
Latency in Blog Application
We can see that with ADBCJ requests are completed faster. For example with JDBC, it takes around 50ms on average to return the result; the ADBCJ version can do it in about 38ms.
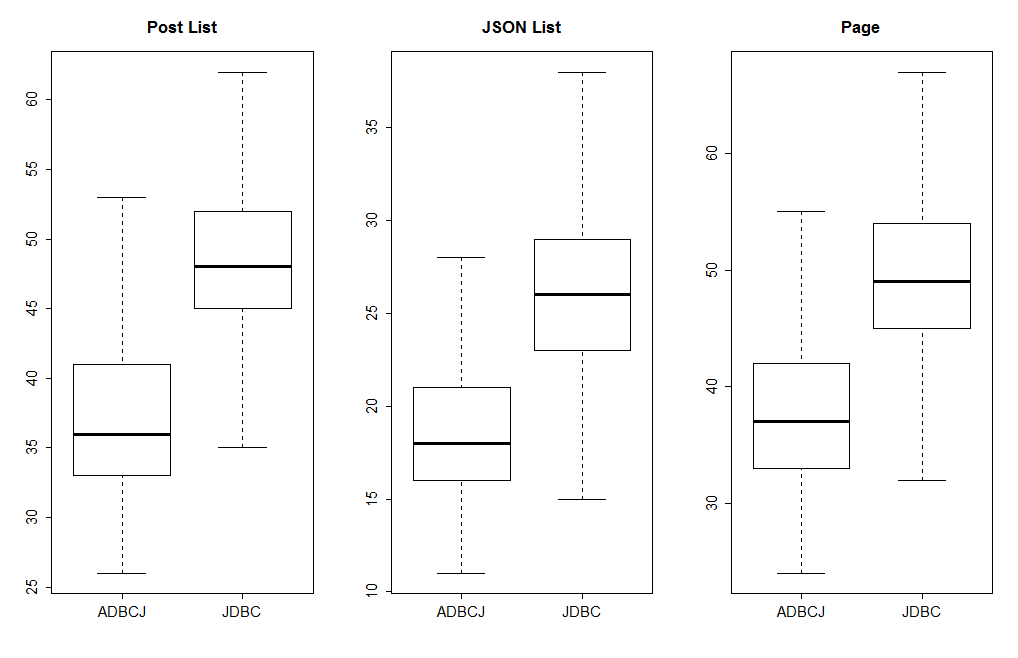
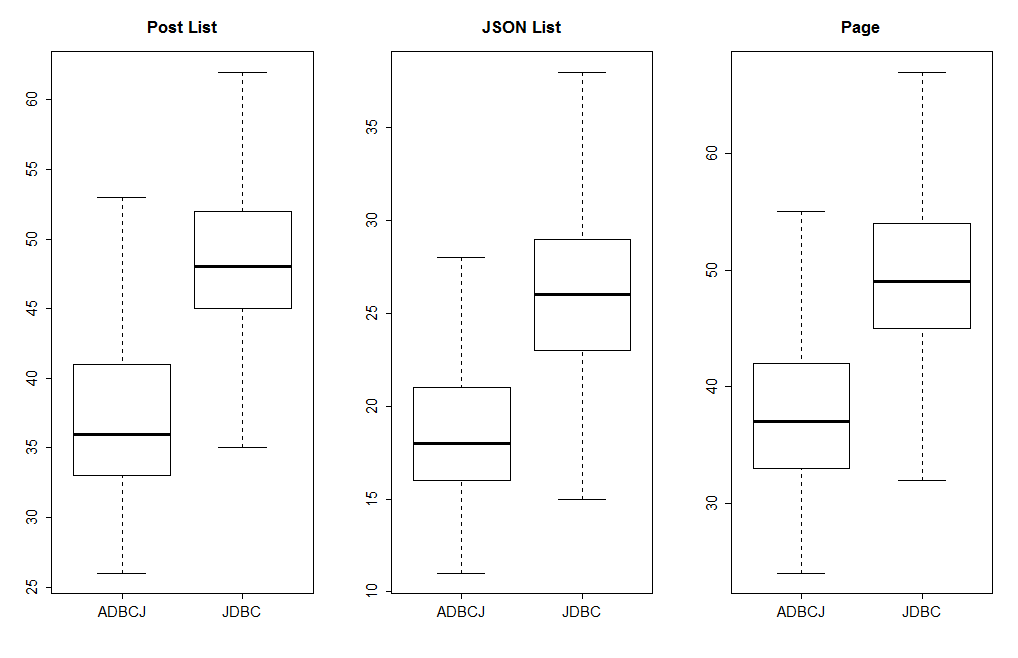
Let’s also look at the throughput. In a small, focused test, where we access the index page in JSON format, ADBCJ performs way better. However, in a more realistic scenario, where we access different pages, the throughput of ADBCJ was about the same.
Blog: Latency vs Throughput
So you are now might tempted to use ADBCJ for a blog like application. Think again, a blog is fairly static application. So we can easily use caching to store the rendered pages. A good cache beats JDBCs and ADBCJs asses! Adding a cache boosts throughput and latency.
Blog: Latency vs Throughput
Blog: Latency With Caching

User Content App
Let’s look at a more dynamic application, a “Facebook” clone. The main page lists posts from the people a person follows. Each post has ‘likes’ and comments. Also the site suggests users to follow. Furthermore it also contains messages, which user can send to each other.
About 50% of the requests require complex read operations, the other 50% are simple writes, like inserting a new comment.
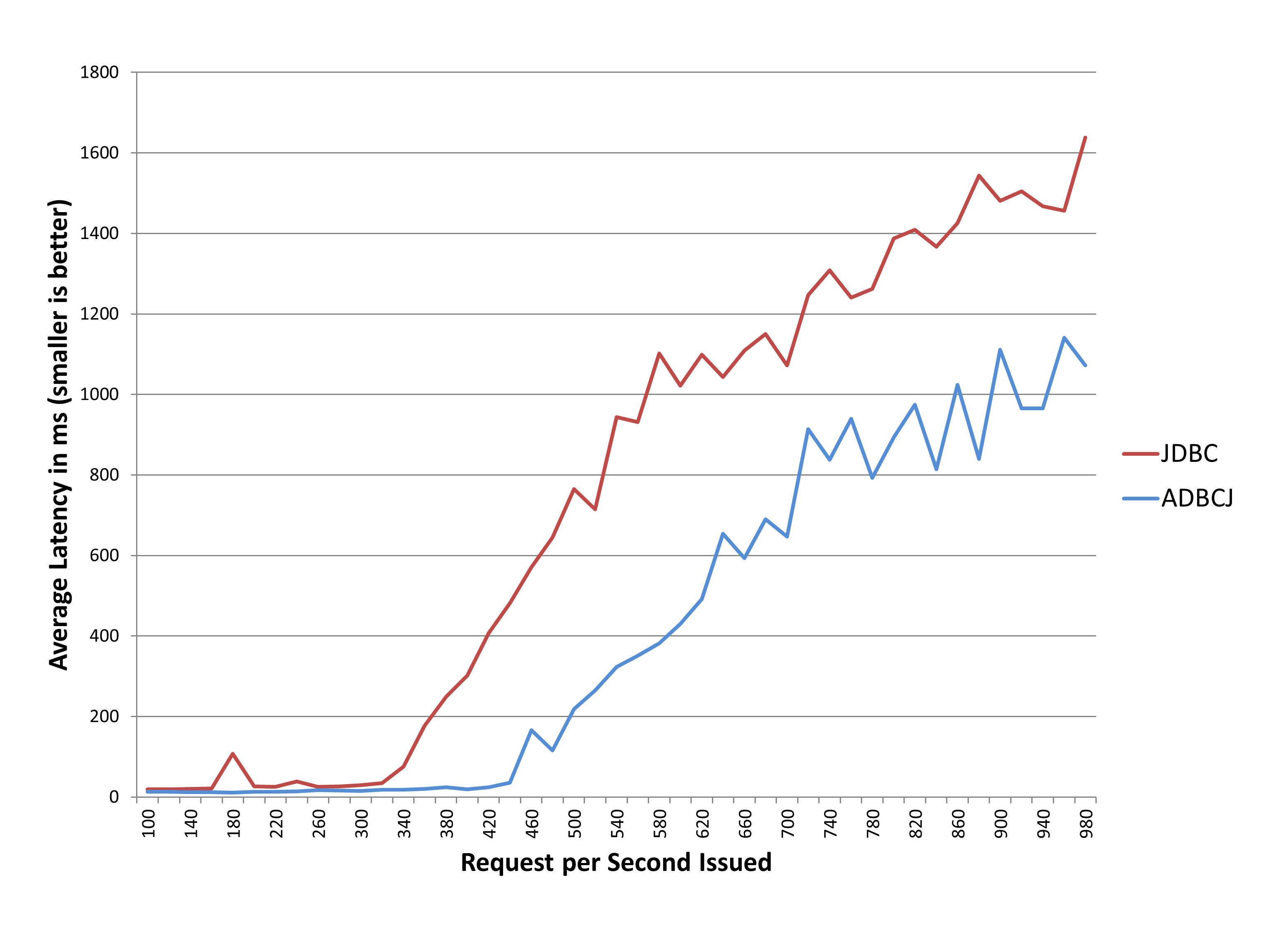
First, let’s look again at the latency. We can see that the complex read operation suddenly is three times faster. However, all writes requests are slowed down. This is maybe a tradeoff which you can make. Reading requests are the ones where users have to wait, while write requests can be done in the background via AJAX.
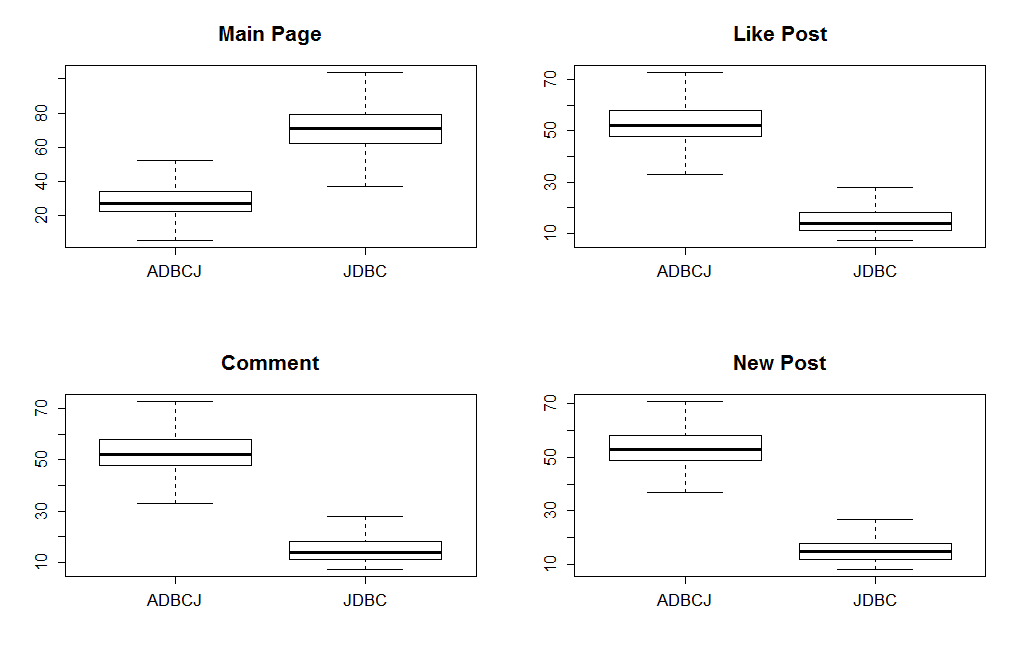
Latency User Content App
So, I wondered if there a fundamental issue with ADBCJ for writes, or if it’s an interaction effect. I ran test with separate read and write requests only. Then ADBCJ has always better latency. So, it seems to be an unfortunate interaction.

Reads / Writes Only
Finally, let’s take a throughput. ADBCJ does way better. Even more, when the system is under pressure, also ADBCJ’s latency for writes start to get better compared to JDBC.

Throughput User Content
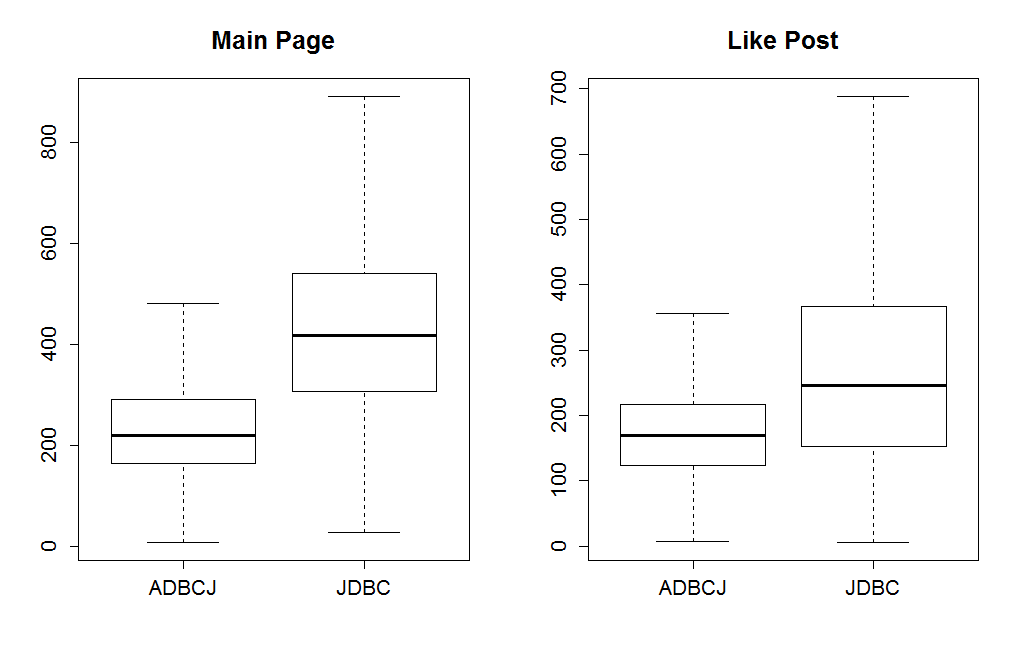
Latency under large Load
Stats Collection App
The last application is a ‘stats collection app’, which collections information about the user’s actions. It is very write heavy, with only some rare, long running reads. Here JDBC and ADBCJ latency was about the same. However, the throughput of ADBCJ was much better.
Stats Collecting
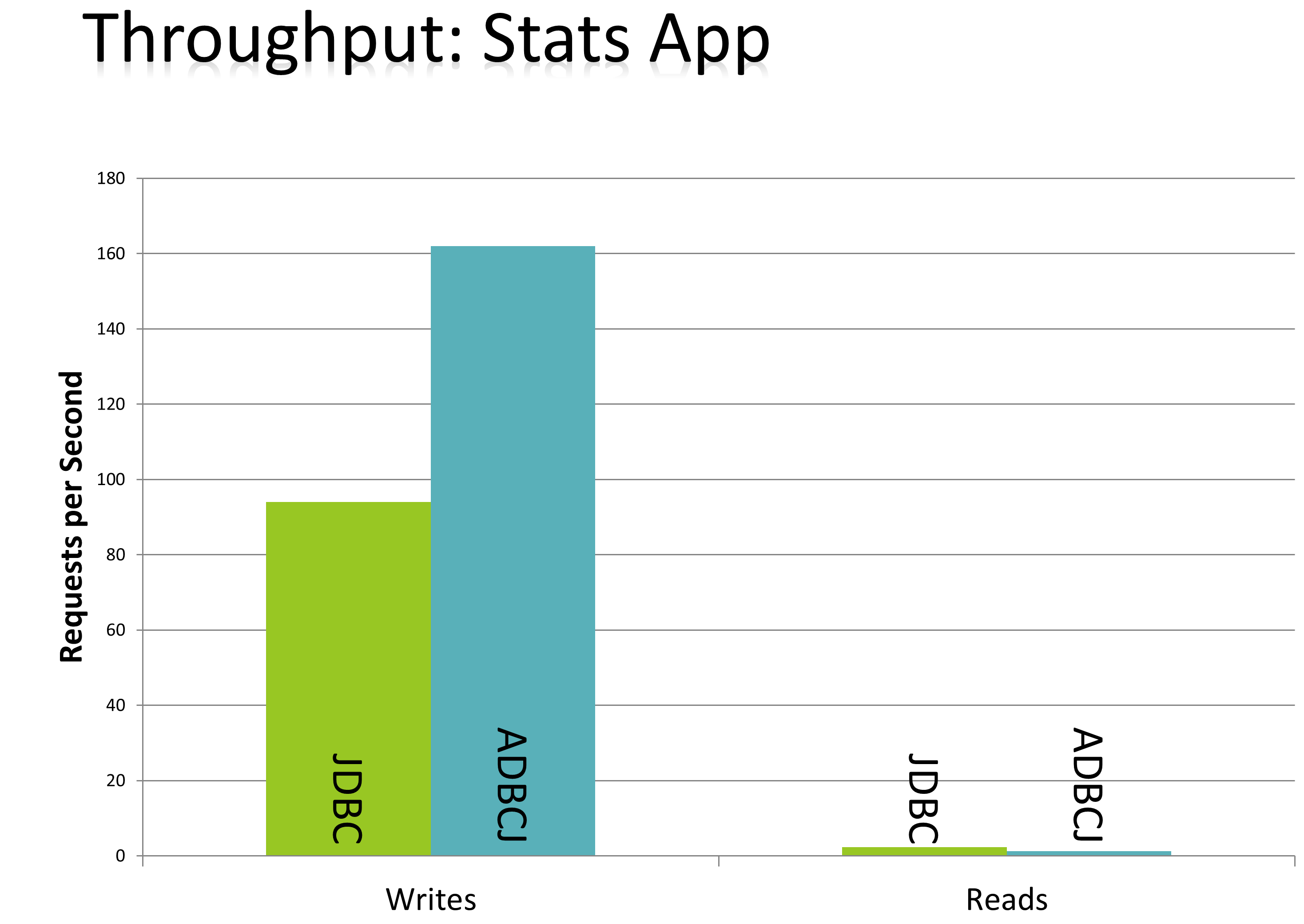
Stats App Throughput
Conclusion
So, ADBCJ can speed up your web applications. Of course, only the data serving parts. Keep in mind caching, avoiding requests etc). Of course you need to do your own experiment for your use case. Next time I’m going to explain why ADBCJ can support better latency and throughput, with code examples. Stay tuned!